纯纯傻逼课
Chapter-4: 语法分析
到了这一章, 算法就变多了起来, 所以在脉络之外又会多一个算法环节.
大体上讲, 语法分析有三条路:
- 通用
- 自顶向下
- 自底向上
其中通用方法由于效率太低而难以被实用, 所以实际上只有后面两种.
而比较高效的算法会转而处理某些文法子类, 幸好这些文法子类表达能力足够强, 能够满足大部分语法构造了.
4.1 一些概念和准备
首先我们来看二义性:
所谓二义性, 就是一个句子可以对应多个语法树, 从而有着不同的结构.
大部分语法分析器都期待无二义文法, 但有时, 在二义性文法上加上一些限制会变得更加灵活.
比如就文法:
stmt -> IF expr THEN stmt
-> IF expr THEN stmt ELSE stmt
-> OTHER
对于IF E1 THEN S1 ELSE IF E2 THEN S1 ELSE S2
对于ELSE和THEN的匹配就会有两种, 通常会加上一个”最近匹配”来限制, 从而删除一颗语法树.
接下来看看左递归:
从$A \to A\alpha \mid \beta$最终变成, 从而消除左递归:
\[A \to \beta A' \\ A \to \alpha A' \mid \epsilon\]其本质类似于”提前生成”, 因为A最终一定会以$\beta$开头, 所以直接先生成, 消除掉左递归, 随后不断在右边生成$\alpha$
4.2 自顶向下分析
自顶向下分析需要从最左匹配开始寻找产生式, 所以需要对”如何选择产生式”上下功夫. 这种难题可以通过多次回溯解决, 但过于浪费算力.
自顶向下分析需要先求FIRST和FOLLOW集合:
- FIRST集合
其定义为, 可从一个串推导得到的串的首符号的集合, 是可推导, 而不是最终.
- FOLLOW集合
定义在非终结符上, 为可能在某些句型中紧跟在A右边的终结符号集合.
根据以上两个集合可以针对LL(1)文法构造出一个预测分析器.
- 定义:一个文法G如果是LL(1)的,当且仅当G的任何两个产生式A -> α$\mid$β满足下面的条件:
- FIRST(α)∩FIRST(β)是空集,因此$\epsilon$不可能同时属于两个集合
- 若β可以推导得到$\epsilon$,则FIRST(α)∩FOLLOW(A)是空集,反之亦然
LL(1)文法不是二义的, 且无左递归, 所以将当前文法转换成LL(1)文法. 但不是所有的文法都可以变换为LL(1)文法的
比如对文法:
E -> E + T
T -> T * F
F -> (E) | id
消除左递归有:
E -> TE’
E’ -> +TE’ | ε
T -> FT’
T’ -> *FT’| ε
F -> (E)|id
则:
FIRST(E) = FIRST(T) = FIRST(F) = { ( ,id }
FIRST(E’) = { + , ε }
FIRST(T’) = { * , ε }
FOLLOW(E) = FOLLOW(E’) = { ) , $ }
FOLLOW(T) = FOLLOW(T’) = { + , ) , $ }
FOLLOW(F) = { + , * , ) , $ }
构造有预测分析表:
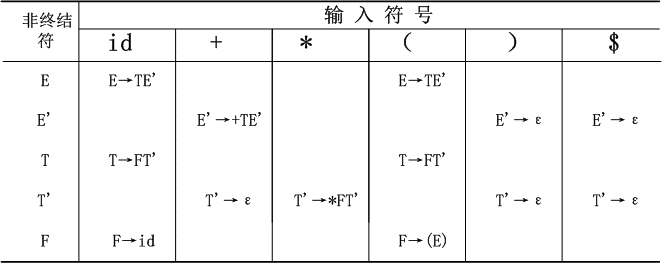
预测分析表的定义详见构造 对于LL(1)文法,M的每个条目都唯一指定了一个产生式, 或标明是一个语法错误
4.3 自底向上的分析
自底向上是从字符串归约到初始变元, 所以核心问题是选择文法符号串的哪一个子串(包括位置)进行归约?
首先先定义: 句柄
- 产生式+位置
- 右句型(最右推导可得到的句型)γ的句柄是一个产生式A -> β以及γ中的一个位置,在这个位置可找到串β,用A代替β得到最右推导的前一个右句型。
如果清楚地知道句柄的位置和应用的产生式的话,可以直接说子串β是αβω的句柄
示例:

4.4 LR分析器
目前我们只知道自底向上的分析过程, 但是不知道如何构造这个分析器.
目前最流行的自底向上语法分析器就是LR(k)语法分析器
首先有项的概念:
- “项”对应了分析的状态,通过这些状态信息的概括,确定LR分析的动作
- A -> .XYZ //表示即将开始分析XYZ
- A -> X.YZ //表示已经分析了X
- A -> XY.Z //表示已经分析了XY
- A -> XYZ. //表示已经分析了XYZ
这种项是LR(0)的基础, 0表示不看向前看符号.
内核项:包括初始项目S’ -> .S和所有点不在左端的项目 非内核项:除了S’ -> .S之外的点在左端的项
构造LR(0)分析器的大致步骤如下:
- 添加头产生式增广文法
- 构造LR(0)项目
- 增加CLOSURE函数和GOTO函数, 从而构造识别项目的DFA
- 从DFA构造出更简洁的分析表
比如对文法:
E -> E + T
T -> T * F
F -> (E) | id
增加E’ -> E后得到项目集规范族如下:
I0: E’ -> .E
E -> .E+T
E -> .T
T -> .T*F
T -> .F
F -> .(E)
F -> .id
I1: E’ -> E.
E -> E.+T
I2: E -> T.
T -> T.*F
I3: T -> F.
I4: F -> (.E)
E -> .E+T
E -> .T
T -> .T*F
T -> .F
F -> .(E)
F -> .id
I5: F -> id.
I6: E -> E+.T
T -> .T*F
T -> .F
F -> .(E)
F -> .id
I7: T -> T*.F
F -> .(E)
F -> .id
I8: F -> (E.)
E -> E.+T
I9: E -> E+T.
T -> T.*F
I10: T -> T*F.
I11: F -> (E).
得到自动机:
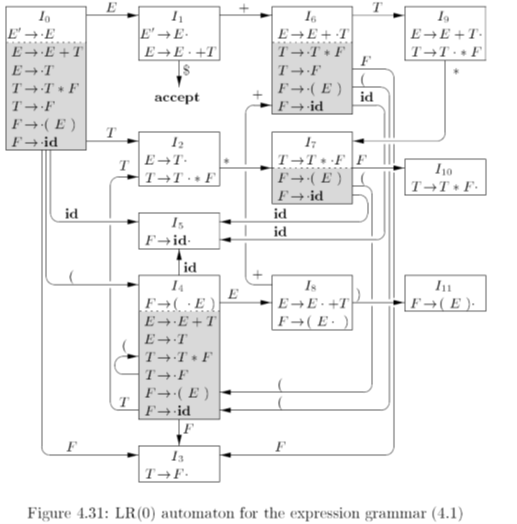
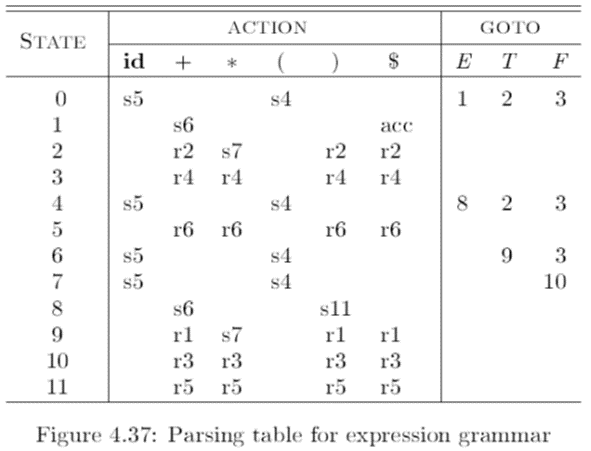
然后约定: (1) si表示移进,把状态i压进栈 (2) rj表示按第j个产生式进行归约 (3) acc表示接受 (4) 空白表示出错
有SLR(1)分析表如下:
也就是基于之前的自动机和表项, 手动排序加入规约后的结果.
4.5 LR(1)语法分析器
实际上, 我们在LR(0)自动机之后, 分析向前看符号得到的SLR(1)分析表虽然利用到了向前看符号. 但实际上, 如果在LR自动机就开始分析向前看符号, 我们就能得到更强大的LR(1)语法分析器.
对文法:
S’ →S
S →CC
C →cC | d
有自动机:
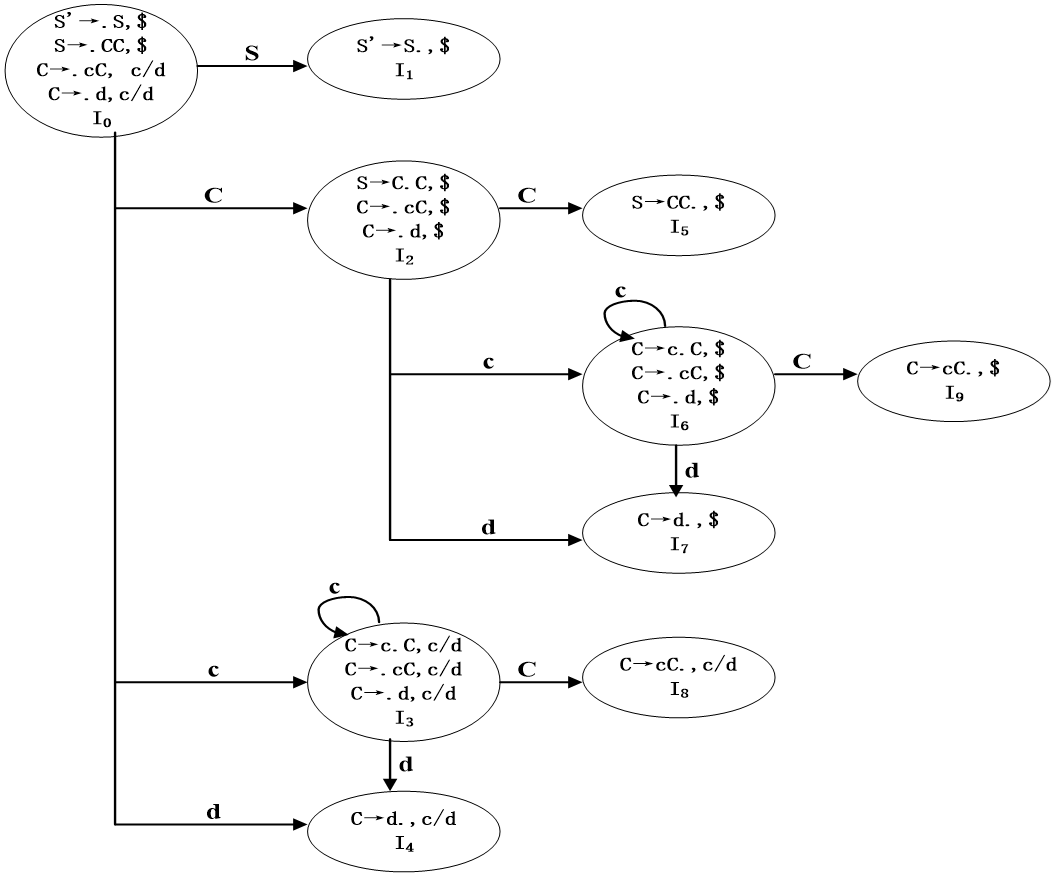
有表:
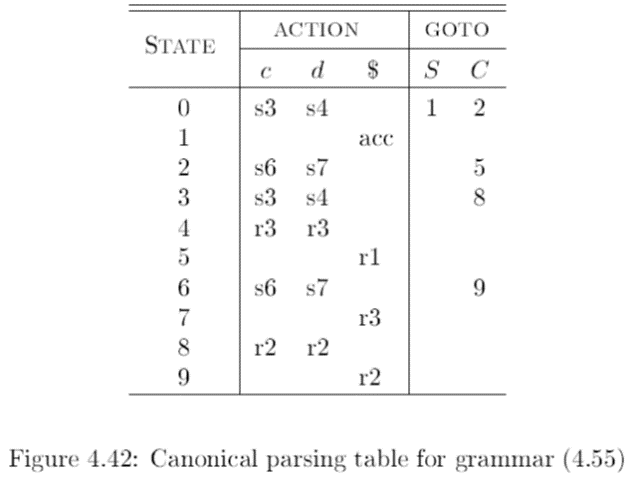
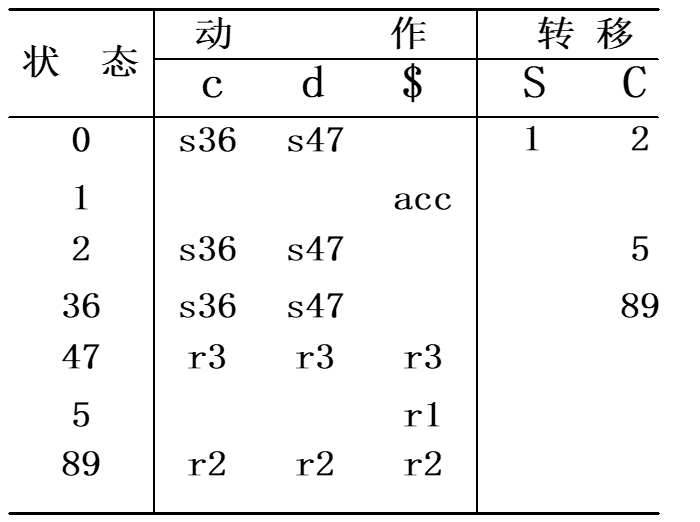
精简状态(合并相同核心项)后得到LALR表:
本章算法
1 左递归
挨个替换即可, 注意是无环无$\epsilon$产生式的
2 求FIRST
- 终结符号是自己
- 非终结符是其生成式的FIRST集合
- 生成$\epsilon$也是自己, 如果其为第一个, 则对第二个文法符号做相同的操作.
3 求FOLLOW
- 首先将$放进 FOLLOW(S) 中
- 由于产生式左侧是单个, 所以左侧作为已知信息
- 对右侧考虑, 出现$B\beta$则将$\beta$的FIRST加入到B的FOLLOW中
- 如果右侧以非终结符结尾(或等价的有$\epsilon$产生), 则产生式左侧的的FOLLOW加入右边
4 LL(1)预测分析表构造
- 输入:文法G
- 输出:预测分析表M
- 方法:对文法G的每个产生式A -> α,进行如下处理: 1. 对FIRST(α)的每个终结符a,把A -> α加入到M[A,a]中 2. 如果ε在FIRST(α)中,对FOLLOW(A)的每个终结符b(含$), 3. 把A -> α加入到M[A,b]中
在完成上述操作后,如果M[A,a]中没有产生式,则将其置 为error(意为语法错误,通常用空条目表示) A表示非终结符, a表示终结符, 该位置上为对应的产生式
5 构造项集
求CLOSURE和GOTO
6 构造CLOSURE
6.1 LR0
找.后面的变元反复加入即可
6.2 LR1
需要考虑一个向前看符号 所以还需要将变元后面的FITST加入