这学期的计算机组成原理要求我们用Verilog实现一个简单的CPU:
- 1-2,我们需要考虑一个简单的ALU和一个寄存器。
- 3-6, 简单的,单周期的,简陋的,用verilog语言描述的CPU
- 7-9, 给简单CPU引入有访存延时的真实内存。并通过IO映射的办法,访问外设。
- 10-13, 用RISCV32的37条指令来写一个简单的CPU。
1 32x32寄存器
我们只需要一个“ 2读1写” :两个读端口 + 一个写端口。
32× 32-bit寄存器堆的输入输出端口定义如下:
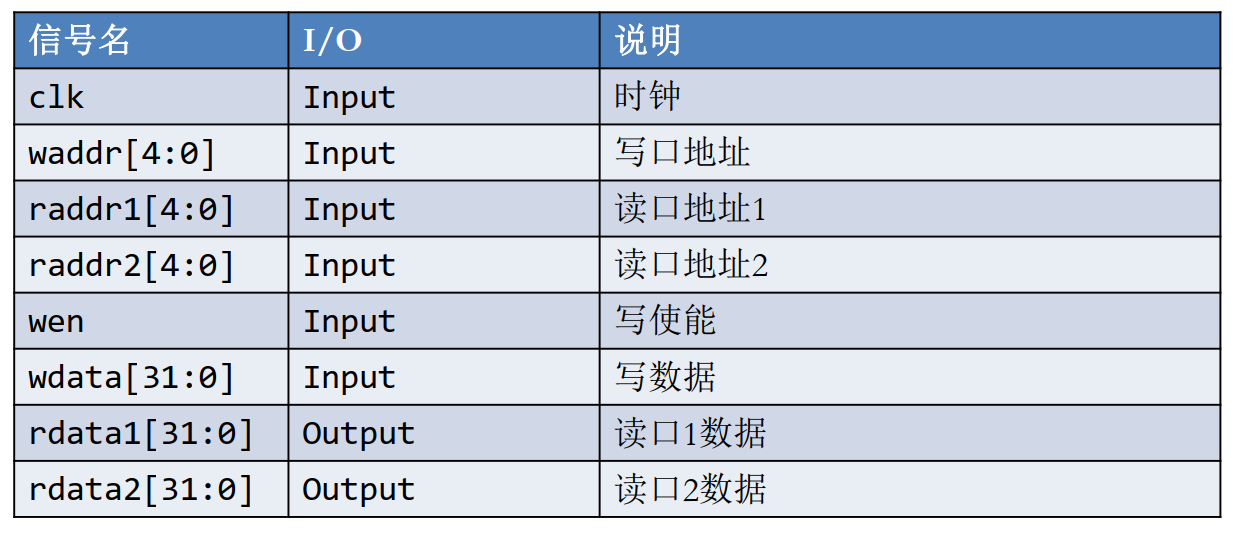
有一个小要求:
- 仅当wen=1(有效)且waddr不等于0时,才可以向waddr对应的寄存器写入wdata
`timescale 10 ns / 1 ns
`define DATA_WIDTH 32
`define ADDR_WIDTH 5
`define REG_NUM 32
module reg_file(
input clk,
input [`ADDR_WIDTH - 1:0] waddr,
input [`ADDR_WIDTH - 1:0] raddr1,
input [`ADDR_WIDTH - 1:0] raddr2,
input wen,
input [`DATA_WIDTH - 1:0] wdata,
output [`DATA_WIDTH - 1:0] rdata1,
output [`DATA_WIDTH - 1:0] rdata2
);
reg [`DATA_WIDTH-1:0]register[`REG_NUM-1:0];
always @(posedge clk) begin
if(wen == 1 && waddr != 0)
register[waddr] <= wdata;
//else ;这里是为了保证模块内部的“纯净”
//register[0] <= 32'b0;
end
assign rdata1 = (raddr1 != 0)?register[raddr1]:(32'b0);
assign rdata2 = (raddr2 != 0)?register[raddr2]:(32'b0);
endmodule
2 简单ALU
其端口定义如下:
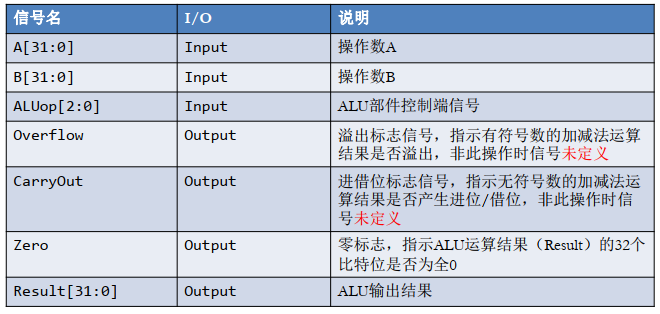
各种操作须知:
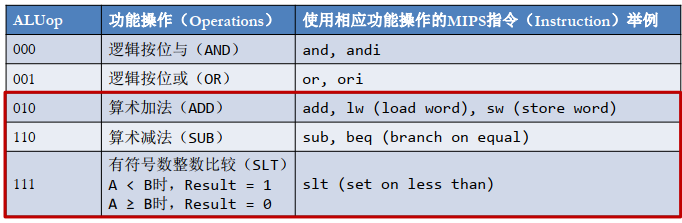
2.1 代码实现解释
首先是两个逻辑运算:
assign Res_and = A&B; // 直接按位与
assign Res_or = A|B; //直接按位或
接着是考虑两个逻辑结果的取舍:
assign Mid_logic = ( (Res_and &{32{~ALUop[0]}}) | (Res_or &{32{ALUop[0]}}) )&{32{~ALUop[1]}};
这里是考虑ALUop[0]的不同,进行一个位扩展+与运算。
接下来是算术运算的核心:在计算机中,只有补码和无符号数两种存储方式。
2.1.1 无符号数解释
同样的,和原码做补码代替减法一样,不过对无符号数的运算不太一样。它称为取补。核心运算图如下:
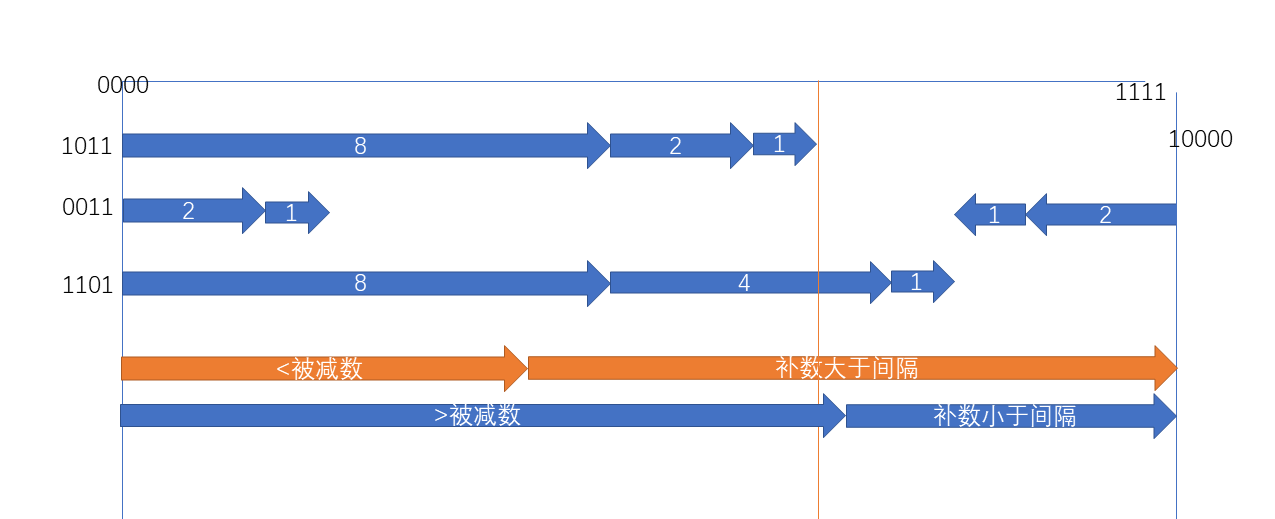
-0011的取补运算就是按位取反再加1,得到1101,我们在图上考虑这些事情,观察取补运算的核心,这样就可以很方便地得到进位和借位的判断。
我们考虑任何一个无符号数。默认箭头朝右,当作为减数的时候,就将箭头倒向左。这时候补运算的核心就凸显出来了。
直接取一个向右的无符号数与减数的真值互补即可。这时候,如果减数较小,那么其长度小于被减数,所以其补要大于被减数离10000的差距。所以取补加起来必然会产生进位。
反过来,如果减数较大,那么其补要小于差距,所以取补加起来不会产生进位。
得到无符号数做减法时,进位1为正常,否则就为借位。而做简单的加法则相反。对于算术ALUop来说,差距在ALUop[2]上,这也就完成了对CarryOut的解释。
assign CarryOut = ALUop[2]^prob_cout;
2.1.2 有符号数解释(补码)
接下来考虑有符号数,这里我们直接越过原码的思维。
切记:在理解计算机存储数字的路程上,原码只是一个小小的跳板,补码才是核心,原码时一个”多余”的东西,建议直接抛弃。
对补码的核心理解是最高位的理解,它的权值是$-2^{n-1}$。那么用同样的图可知:
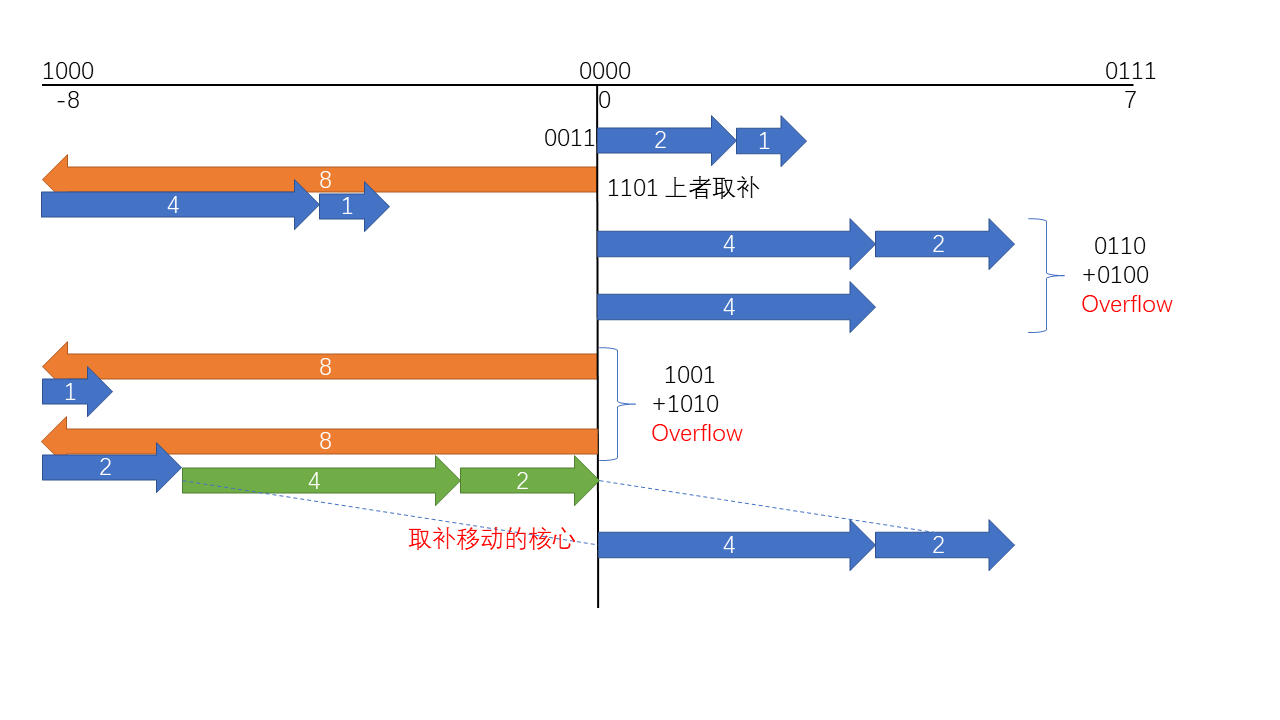
按0011取补得到1101,从中可以看出补码加法的朴实:
- 如果正数大,那么后三位进位就把负权值的高位消掉了,如果负数大就消不掉,但是可以使正值部分增加,从而让负数变大。
接下来看两种溢出情况:
- 如果两正数产生了负权值的进位,那么就必然是溢出;
- 如果两负数的负权值位相加进位被抹去,而正值位的进位没有补上,就会得到正数,那么也属于溢出。
其上的情况都可以在图上表示出。
最后从图上可以看出取补运算移动的核心。
最终得到了:
assign Overflow = ((~A[31])&(~B[31])&Res_cal[31]&(~ALUop[2]))
| ((A[31])&(B[31])&(~Res_cal[31])&(~ALUop[2]))
| ((A[31])&(~B[31])&(~Res_cal[31])&(ALUop[2]))
| ((~A[31])&(B[31])&(Res_cal[31])&(ALUop[2]));
//就是把四种情况单独拿出来
从上我们得到了取补运算的合理性,所以用朴素的选择语句:
assign {prob_cout,Res_cal} = A+( (B^{32{ALUop[2]}})+{{31{1'b0}},{ALUop[2]}} );
这里提一句和补码变化的区别;
可以看出取补运算按位取反+1得到的结果相当于1111-$x_3x_2x_1x_0+1$,相当于$1\ 0000-x_3x_2x_1x_0$
而补码运算则考虑了原码符号位的问题,还需要把符号位消去后,再按位取反再+1,所以是$10\ 0000-x_3x_2x_1x_0$
其余的信号和选择都比较好理解,从而得到以下的所有代码:
3 代码示例
`timescale 10 ns / 1 ns
`define DATA_WIDTH 32
module alu(
input [`DATA_WIDTH - 1:0] A,
input [`DATA_WIDTH - 1:0] B,
input [ 2:0] ALUop,
output Overflow,
output CarryOut,
output Zero,
output [`DATA_WIDTH - 1:0] Result
);
// TODO: Please add your logic design here
// 由于线路过于复杂,所以用几个中间变量进行稍微的简化。
wire [`DATA_WIDTH-1:0] Res_and,Res_or,Res_cal;
wire [`DATA_WIDTH-1:0] Mid_logic, Mid_cal;
wire prob_cout;
// 之后以test为名的信号都是用来测试的,对运算优先级的考察和中间结果运算正误判断起到了积极作用。
//wire [`DATA_WIDTH-1:0] test,test_1,test_2;
assign Res_and = A&B; // 直接按位与
assign Res_or = A|B; //直接按位或
assign {prob_cout,Res_cal} = A+( (B^{32{ALUop[2]}})+{{31{1'b0}},{ALUop[2]}} );//这里是根据ALUop的位数不同来选择是对B进行取补运算。
//这里考虑溢出OF,也就是有符号数的问题。
// 直接考察四种情况,还可以对这四种情况写标准bool式。这里就不化简了。
// 0 + 0 = 1; 只对一个式子做解释,也就是正数+正数却得到了负数。
// 1 + 1 = 0;
// 1 - 0 = 0;
// 0 - 1 = 1;
assign Overflow = ((~A[31])&(~B[31])&Res_cal[31]&(~ALUop[2])) | ((A[31])&(B[31])&(~Res_cal[31])&(~ALUop[2])) | ((A[31])&(~B[31])&(~Res_cal[31])&(ALUop[2])) | ((~A[31])&(B[31])&(Res_cal[31])&(ALUop[2]));
// 考虑进位/借位,直接观察+法中的进位即可;例外的情况是当作减法来看的情况,这种情况的溢出体现在最高位的0上。因为“不够减”。
assign CarryOut = ALUop[2]^prob_cout;
// 考虑逻辑的最终输出结果。只需要对ALUop第二位的不同做分析即可。
assign Mid_logic = ( (Res_and &{32{~ALUop[0]}}) | (Res_or &{32{ALUop[0]}}) )&{32{~ALUop[1]}};
// considering the logic part-> 这里只是纠错的中途步骤
// assign test = (B^{32{ALUop[2]}}) + {{31{1'b0}},{ALUop[2]}};
// assign test_1 = B^{32{ALUop[2]}};
// assign test_2 = {{31{1'b0}},{ALUop[2]}};
// 同理,也需要考虑ALUop的第二位来判断是否有计算输出;但不同的是,还需要考虑SLT的情况,也就是一个取或,本质上是根据ALUop第三位的01判断是输出Res_cal或者单纯的SLT结果
// 也就是(Res_cal[31]^Overflow),比大小的过程中也需要考虑Overflow,如果其为0,则只需要看高位即可,否则还需要考虑它。
assign Mid_cal = ( (Res_cal & ( { 32{~ALUop[0]} } )) | {{31{1'b0}},{(ALUop[0]&(Res_cal[31]^Overflow))}} ) & {32{ALUop[1]}};
// 最后对两个结果进行一个选择即可。
assign Result = (Mid_logic|Mid_cal);
assign Zero = (~(| Result));
endmodule
3 修改ALU
更新操作如下:
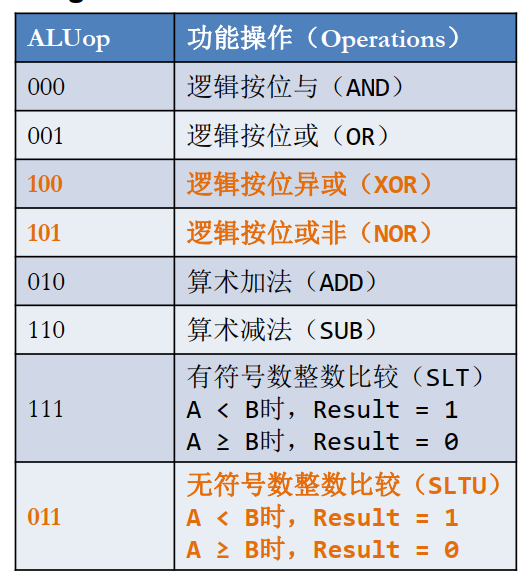
对于无符号数,见ALU
alu代码如下:
......
module alu(
......
);
// TODO: Please add your logic design here
// 由于线路过于复杂,所以用几个中间变量进行稍微的简化。
wire [`DATA_WIDTH-1:0] Res_and,Res_or,Res_cal,Res_xor,Res_nor;
wire [`DATA_WIDTH-1:0] Mid_logic, Mid_cal;
wire Mid_comp;
wire prob_cout;
// 之后以test为名的信号都是用来测试的,对运算优先级的考察和中间结果运算正误判断起到了积极作用。
//wire [`DATA_WIDTH-1:0] test,test_1,test_2;
assign Res_and = ( (A&B) &{32{~ALUop[0]}} ); // 直接按位与
assign Res_or = (A|B) & {32{ALUop[0]}}; //直接按位或
assign Res_xor = (A^B) &{32{~ALUop[0]}}; //直接按位异或
assign Res_nor = (~(A|B)) & {32{ALUop[0]}}; //对或信号取反
assign {prob_cout,Res_cal} = A+( (B^{32{ALUop[2] | ALUop[0]}})+{{31{1'b0}},{ALUop[2] | ALUop[0]}} );//这里是根据ALUop的位数不同来选择是对B进行取补运算。
//......
assign Overflow = ((~A[31])&(~B[31])&Res_cal[31]&(~ALUop[2])) | ((A[31])&(B[31])&(~Res_cal[31])&(~ALUop[2]))
| ((A[31])&(~B[31])&(~Res_cal[31])&(ALUop[2])) | ((~A[31])&(B[31])&(Res_cal[31])&(ALUop[2]));
// 考虑进位/借位,直接观察+法中的进位即可;例外的情况是当作减法来看的情况,这种情况的溢出体现在最高位的0上。因为“不够减”。
assign CarryOut = ALUop[2]^prob_cout;
// 考虑逻辑的最终输出结果。只需要对ALUop第二位的不同做分析即可。现在需要对ALUop[0]和2进行分析。
//而且也要加一个选择了;
assign Mid_logic = ( (( Res_and|Res_or ) & {32{~ALUop[2]}} )
| (( Res_xor|Res_nor ) & {32{ALUop[2]}} )) & {32{~ALUop[1]}} ;
// 同理,也需要考虑ALUop的第二位来判断是否有计算输出;
//考虑SLT的情况,也就是一个取或,本质上是根据ALUop第三位的01判断是输出Res_cal或者单纯的comp结果
//而对于SLTU,无符号数。有进位,就是A>=B;无进位则是A<B;
//也就是,有进位,prob_cout=1;A>=B,输出0
//无进位,prob_cout=0,A<B,输出1.
// 也就是(Res_cal[31]^Overflow),比大小的过程中也需要考虑Overflow,如果其为0,则只需要看高位即可,否则还需要考虑它。
// 比较复杂,重新弄个一个Mid_comp;
//assign Mid_cal = ( ( Res_cal & ( { 32{~ALUop[0]} } ) ) | {{31{1'b0}},{(ALUop[0]&(Res_cal[31]^Overflow))}} ) & {32{ALUop[1]}};
assign Mid_comp = ( (Res_cal[31]^Overflow) & ALUop[2] )
| ( ~(prob_cout | ALUop[2]) ) ;
......
endmodule
4 添加Shifter

由于Verilog本身移位需要考虑signed之类的麻烦,故采用通式移位器:
`timescale 10 ns / 1 ns
`define DATA_WIDTH 32
module shifter (
input [`DATA_WIDTH - 1:0] A,
input [ 4:0] B,
input [ 1:0] Shiftop,
output [`DATA_WIDTH - 1:0] Result
);
// TODO: Please add your logic code here
//设置Res_left作为左移结果,Res_right作为右移结果;
//设置Complement为移位补全位;
wire [`DATA_WIDTH - 1:0] Res_left, Res_right;
wire [`DATA_WIDTH - 1:0] Res_left_1,Res_left_2,Res_left_3,Res_left_4;
wire [`DATA_WIDTH - 1:0] Res_right_1,Res_right_2,Res_right_3,Res_right_4;
wire Complement;
//左移Lop就是Shiftop[0],直接补零即可
//右移则是在Shiftop[0]的基础上,看Shiftop[1]&A[31]后。而且,补1的唯一情况就是算术移位+最高位是1;
assign Complement = (&Shiftop)&A[31];
//最后只需要考虑左右移了。采用桶式移位器!
//桶式移位器,可以使用一个变量名选择到底;另外,assign可以直接声明变量,不过位长会跟不同IDE的实现有关。
assign Res_left_1 = (B[4]==1)?({{A[15:0]},{16{Complement}}}):(A);
assign Res_left_2 = (B[3]==1)?({{Res_left_1[23:0]},{8{Complement}}}):(Res_left_1);
assign Res_left_3 = (B[2]==1)?({{Res_left_2[27:0]},{4{Complement}}}):(Res_left_2);
assign Res_left_4 = (B[1]==1)?({{Res_left_3[29:0]},{2{Complement}}}):(Res_left_3);
assign Res_left = (B[0]==1)?({{Res_left_4[30:0]},{1{Complement}}}):(Res_left_4);
assign Res_right_1 = (B[4]==1)?({{16{Complement}},{A[31:16]}}):(A);
assign Res_right_2 = (B[3]==1)?({{8{Complement}},{Res_right_1[31:8]}}):(Res_right_1);
assign Res_right_3 = (B[2]==1)?({{4{Complement}},{Res_right_2[31:4]}}):(Res_right_2);
assign Res_right_4 = (B[1]==1)?({{2{Complement}},{Res_right_3[31:2]}}):(Res_right_3);
assign Res_right = (B[0]==1)?({{1{Complement}},{Res_right_4[31:1]}}):(Res_right_4);
assign Result = (Shiftop[1]==1)?(Res_right):(Res_left);
endmodule
5 设计CPU
接下来就涉及到CPU的设计了。
CPU实验的核心在以下几个方面:
- 译码
- 不能逐条译码,不够优雅;
- 操作
- 尤其要注意内存寄存器堆的读写
- 数据通路
以下是各端口的要求:
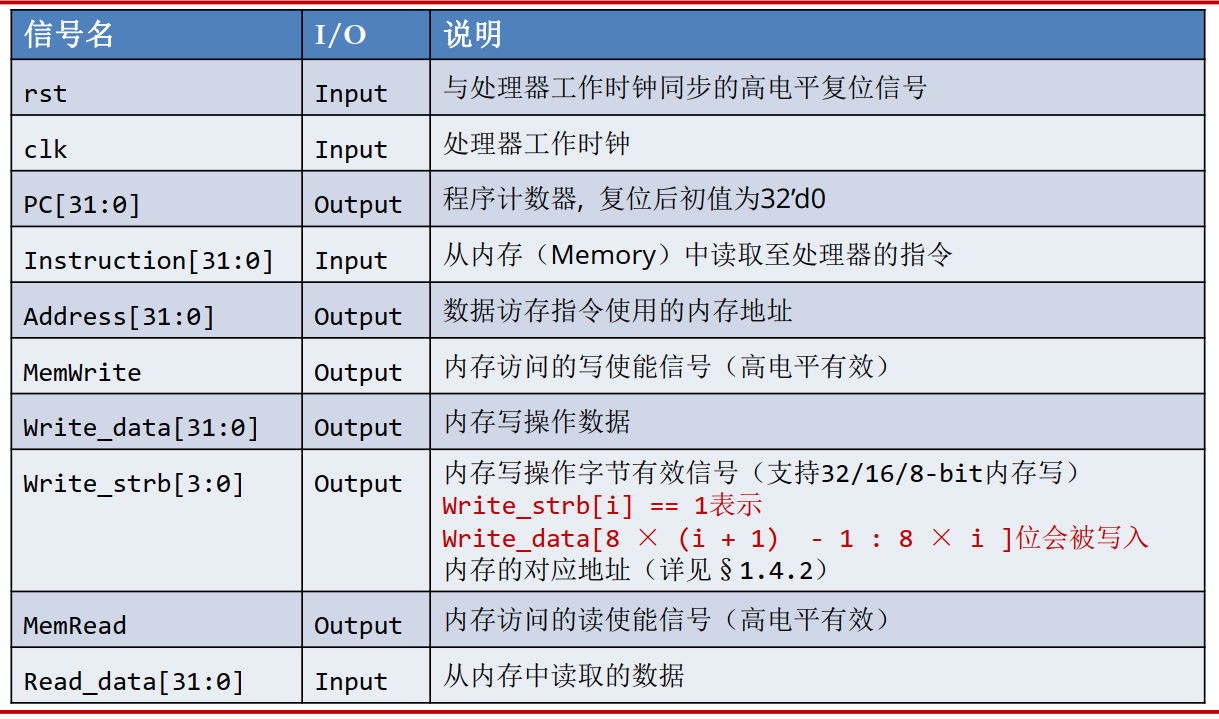
我们首先来尝试译码:
5.1 译码
先翻译R-type指令:
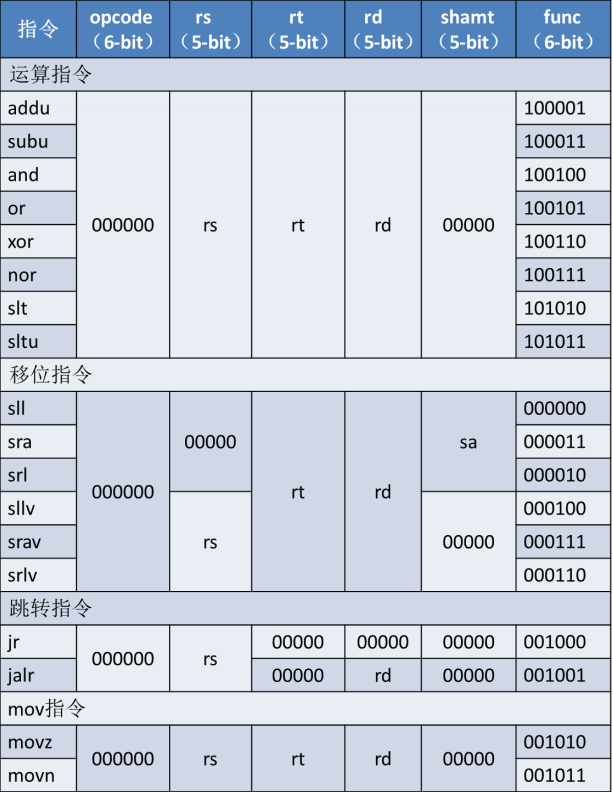
从后面可以看出,大部分寄存器的位置都是固定的。
采用一个R_type的信号作为标志,之后也是类似,由此可完成大多数译码。
//1.把R-type译出来;
//R-高度一致的合并代码
wire R_type = (opcode == 6'b000000);//所有R_type都会产生寄存器写
//reg_raddr1/wire [4:0] R_raddr1 = rs;
//reg_raddr2/wire [4:0] R_raddr2 = rt;
//RegDst/wire [4:0] R_waddr = rd;
//运算指令
wire R_calc = R_type & func[5];//只有opcode都是0时,且func高位是1,Rtype才是1;写入alu_result
wire [2:0] R_alu_op = {6{R_calc}} & //只有R为真,才是直接使用的alu
(func[2]?{func[1],!func[2],func[0]}://逻辑运算译码
(!func[3]?{func[1],!func[2],!func[0]}:{!func[0],!func[2],func[1]})//slt有一点特殊
);//
//移位指令, 考虑到只有它在用移位器,于是
wire R_shift = R_type&(func[5:3] == 3'b000);
assign Shifter_Shiftop = func[1:0];
wire variable = R_shift & func[2];//考虑是否使用移位变量;
assign Shifter_A = reg_rdata2;
assign Shifter_B = variable?reg_rdata1[4:0]:sa;
//RF_wdata/wire [31:0] R_shift_result = Shifter_Result;//写入Shifter_Result
//跳转指令
wire R_jump = R_type&&(func[5:1] == 5'b00100);
wire [31:0] Rj_JumpAddr = reg_rdata1;//感觉此处并不需要特别地处理func[0],可能是到后面选择的时候用吧。
wire Rj_ret = R_jump&func[0];//写入pc_8
//RF_wdata/wire [31:0] Rj_wdata = pc_8;
wire R_wen = R_jump?func[0]:R_type;
//mov指令
wire R_mov = R_type&&(func[5:1] == 5'b00101);
wire rt_Zero = ~(|reg_rdata2);//如果rt读出数据是0,那么Zero就是1
wire mov = R_mov&(rt_Zero^func[0]);//此时就可以靠异或来得到是否mov,此处也是在后面用到的信号。
//RF_wdata/wire [31:0] Rm_wdata = reg_rdata1;//写入reg_rdata1
需要注意的是,Jr指令是不讲wen拉高的。而jalr是拉高的。
5.2 逐条实践
这里也简单说明几条难实现的指令。
5.2.1 IL指令
lb,lh,lbu,lhu这四条指令都是读出reg,然后将他们放入内存写数据的低位。然后该怎么扩展怎么扩展。
lwl和lwr则是非同常人能设想出的指令,他在大端和小端系统完全不同。
lwl:To load the most-significant part of a word as a signed value from an unaligned memory address
从内存中取出数据,也就是载入到内存中最为重要的字节上。一般来说,我们把左边视作MSB,所以是lw-left。
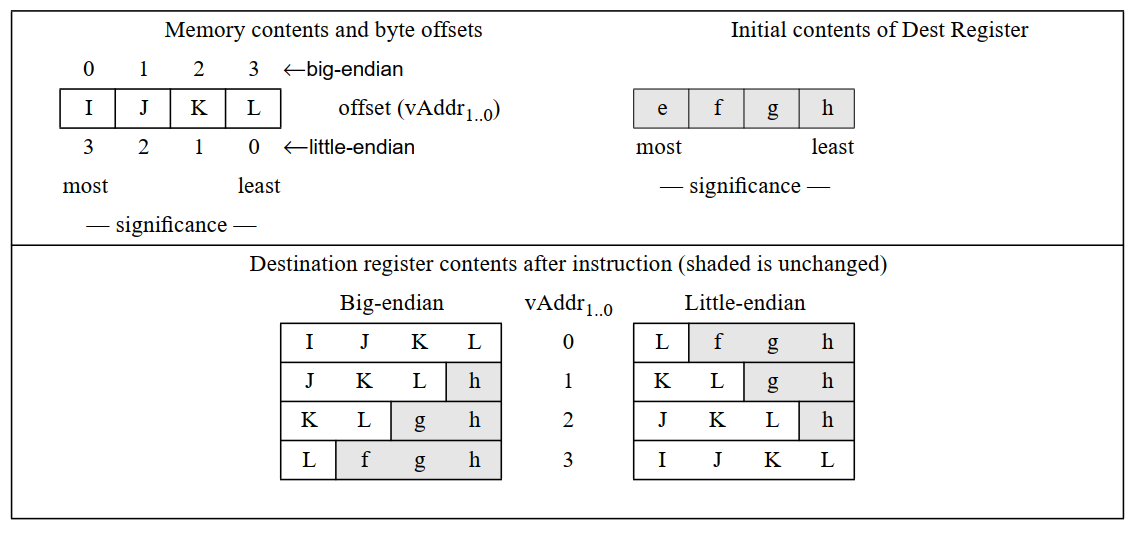
考虑数据IJKL,其中I是最重要的,按照大小端:
- big-endian:I被置于小地址;
- little-endian:I被置于大地址。
大小端可以考虑小地址处的数据。大端则是存最重要的;小端则是存不重要的。
先考虑小端的情况:
我们看,当地址尾巴为11时,我们向低地址区读入,所以是将mem读入的全部内容载入reg。
而00时,也是向低地址区,所以只会读入最低的L进入reg,当然是当作最高位来处理的。
再考虑大端:
它是向高地址对齐,所以11只读入一位;而00读入全部。
从这个意义上来看,它载入的方向都是向着LSB的方向读入的。
所以LWL的全部阐述为:按地址访存,将当前地址到LSB地址中间的内容全部取出,作为高位放入reg中。
wire [31:0] IL_mask_rl_data = //前面是lwr,
(ILS_Address[1:0]==2'b11 ?(opcode[2]?{reg_rdata2[31:8],IL_read_data[31:24]}:IL_read_data)
:(ILS_Address[1:0]==2'b10 ?(opcode[2]?{reg_rdata2[31:16],IL_read_data[31:16]}:{IL_read_data[23:0],reg_rdata2[7:0]})
:(ILS_Address[1:0]==2'b01 ?(opcode[2]?{reg_rdata2[31:24],IL_read_data[31:8]}:{IL_read_data[15:0],reg_rdata2[15:0]})
:(opcode[2]?IL_read_data:{IL_read_data[7:0],reg_rdata2[23:0]}))));
这时考虑LWR则比较轻松,只不过方向是向着MSB方向取数。
由于是小端,11时就只读入一位作为最低位了。
那么完全的叙述为:
LWR:按地址访存,将当前地址到MSB地址的内容全部取出,作为低位放入目标reg。
5.2.2 IS指令
sb,sh,sw则是根据计算出的地址进行选择。
sb:00是mask为0001,数据也是放入最低位。需要注意的是,放入的总是内存中的低位。
wire [3:0] IS_mask_b_strb =
(ILS_Address[1:0]==2'b00 ?4'b0001
:(ILS_Address[1:0]==2'b01 ?4'b0010
:(ILS_Address[1:0]==2'b10 ?4'b0100:4'b1000)));
wire [31:0] IS_b_data =
(ILS_Address[1:0]==2'b00 ? {{24{1'b0}},reg_rdata2[7:0]}
:(ILS_Address[1:0]==2'b01 ?{{16{1'b0}},reg_rdata2[7:0],{8{1'b0}}}
:(ILS_Address[1:0]==2'b10 ?{{8{1'b0}},reg_rdata2[7:0],{16{1'b0}}}
:{reg_rdata2[7:0],{24{1'b0}}})));
sh:放入的总是内存低位
wire [3:0] IS_mask_h_strb = ILS_Address[1:0]==2'b10 ?4'b1100:4'b0011;
wire [31:0] IS_h_data = (ILS_Address[1:0] == 2'b10)?{reg_rdata2[15:0],{16{1'b0}}}:{{16{1'b0}},reg_rdata2[15:0]};
swl:To store the most-significant part of a word to an unaligned memory address
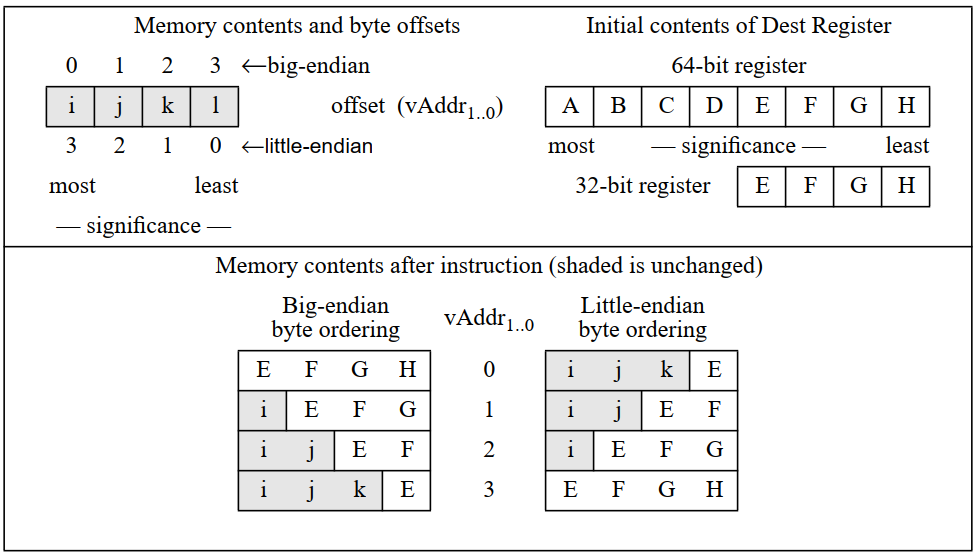
同样的,我们先考虑小端,他是从reg的高位读入。然后考虑内存是向LSB读。
在这一点是,-wl都是一致的。均是从reg的最高位下手,然后向着LSB方向写入。
swl:按地址访存,将当前地址到LSB地址中间的内容全部取出,替换成reg的高位。
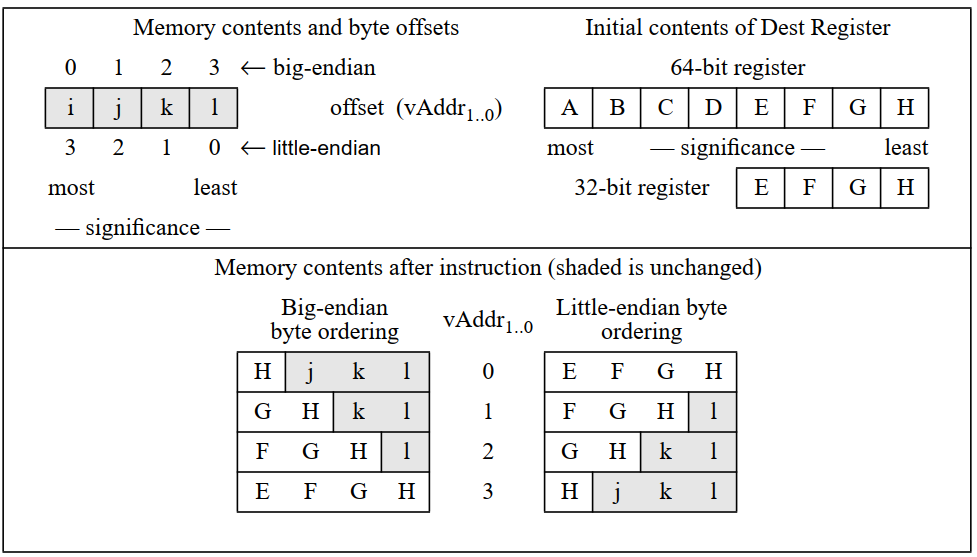
swr:To store the least-significant part of a word to an unaligned memory address
那么SWR的作用也容易揭晓:按地址访存,将当前地址到MSB地址中间的内容全部取出,替换成reg的低位。
wire [3:0] IS_mask = //前面是swr
(ILS_Address[1:0]==2'b11 ?(opcode[2]?4'b1000:4'b1111)
:(ILS_Address[1:0]==2'b10 ?(opcode[2]?4'b1100:4'b0111)
:(ILS_Address[1:0]==2'b01 ?(opcode[2]?4'b1110:4'b0011)
:(opcode[2]?4'b1111:4'b0001))));
wire [31:0] IS_rl_data = //前面是swr,
(ILS_Address[1:0]==2'b11 ?(opcode[2]?{reg_rdata2[7:0],{24{1'b0}}}:reg_rdata2)
:(ILS_Address[1:0]==2'b10 ?(opcode[2]?{reg_rdata2[15:0],{16{1'b0}}}:{{8{1'b0}},reg_rdata2[31:8]})
:(ILS_Address[1:0]==2'b01 ?(opcode[2]?{reg_rdata2[23:0],{8{1'b0}}}:{{16{1'b0}},reg_rdata2[31:16]})
:(opcode[2]?reg_rdata2:{{24{1'b0}},reg_rdata2[31:24]}))));
5.3 数据通路
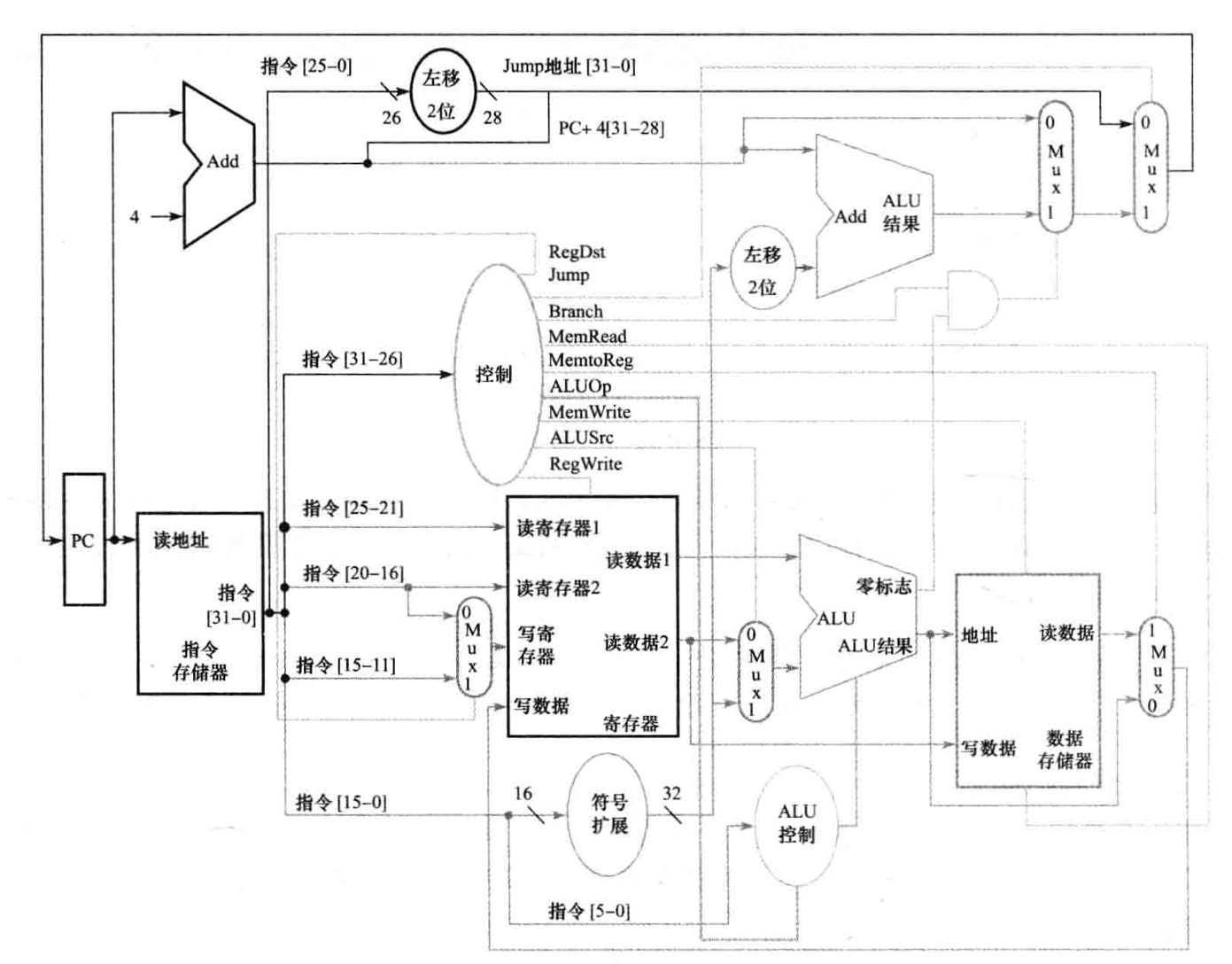
//开始构建数据通路
assign RegDst = R_type & (R_mov?(mov?1'b1:1'b0):1'b1);//看看哪些是写入rt,哪些是写rd。还有一个0和特殊的31号。取1,取rd,考虑mov指令的选择,要在0寄存器。
//考虑实际的Write_register, 并注释掉重复写的地方。
assign RF_waddr = RegDst?rd:(//如果是1,就选rd
(IL || IC)?rt:(//如果是IL和IC,就选rt
(J_type && J_wen)?5'b11111:5'b00000));//如果是JAL,就31,反之则选择0,反正也写不进去。
//只有RI或者IB,J是直接跳转。不过还需要更细致一点,毕竟还需要Zero的保证。
assign Branch = (RI & RI_branch) | (IB & (IB_eq_branch | IB_gl_branch));
//考虑实际的跳转情况,按照之前的构想,我们只需要考虑branch信号和JumpAddr两个信号即可。
assign NEW_PC = Jump?pc_addr:(Branch?pc_branch:pc_4);
assign pc_branch = pc_4 + branch_addr;//IB的跳转目的是一致的。
assign pc_addr = JumpAddr;
//signle cohere/assign branch_addr = RIB_branch_addr;
assign Jump = J_type | R_jump;
assign JumpAddr = J_type?J_next_pc:Rj_JumpAddr;
//Mem_reg_op
assign MemWrite = opcode[5] & opcode[3];
assign MemRead = opcode[5] & (~opcode[3]);
assign RF_wdata = (R_calc || IC_wen)?alu_Result:
(R_shift?Shifter_Result:
((Rj_ret || J_wen)?pc_8:
(mov?reg_rdata1:IL_wdata)));
assign RF_wen = (R_wen | J_wen | IC_wen | IL);//特判一个JR
assign Address = ILS_Address_aligned;
//assign Write_data = IS_write_data;
//assign Write_strb = IS_write_strb;
//ALU的解码
assign ALUSrc = (R_calc | RI | IB);//R_calc, RI, IB 三类指令是R+R;IC, IL, IS三类指令是R+imm;1->2R
assign reg_raddr1 = rs; // rs的读取是注定的,纵使有的地方用的是base,不过也是用来作为标号的。其实还有SLL的不同
assign alu_A = reg_rdata1;
assign reg_raddr2 = RI?5'b00000:rt;//rt确实是注定的。
wire [31:0] Imm = (IC?extended_imm:ILS_extended_imm);
assign alu_B = ALUSrc?reg_rdata2:Imm;
assign ALUop = R_calc?R_alu_op:
(RI?RI_alu_op:
(IB?IB_alu_op:
(IC?IC_alu_op:3'b010)));
assign alu_ALUop = ALUop;
这就完成了单周期的全部解释。
6 多周期CPU
但上述CPU的实用性很弱,这是因为clk的周期被最长的指令操作限制了。
根据加速大多数原则,我们尝试把它分成五个部分,那么最长的部分就由小部分决定。
这便是多周期的原理,多周期+流水线的配置是十分自然的,尽管后者的实现十分复杂。
6.1 状态机
我们按如下跳转状态图来构造。
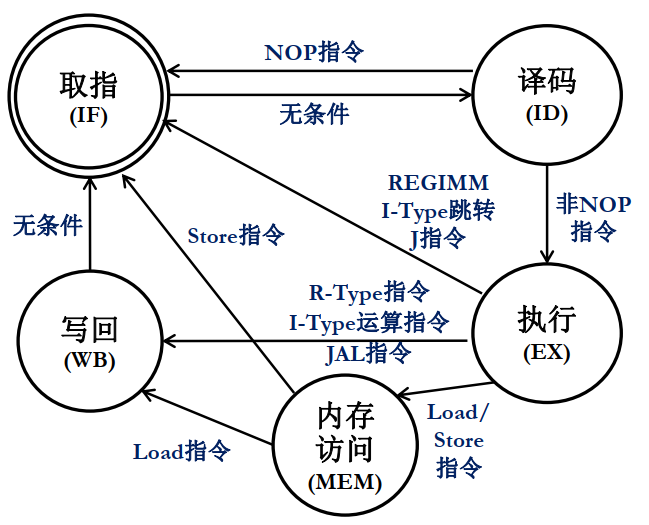
用verilog实现状态机分为三步:
- next跳转
- 状态行为
- 可能的状态输出
/*
* ============================================================================
* 1.声明状态和next跳转
* ============================================================================
*/
localparam IF = 5'b00001;
localparam ID = 5'b00010;
localparam EX = 5'b00100;
localparam MEM = 5'b01000;
localparam WB = 5'b10000;
reg [4:0] current_state;
reg [4:0] next_state;
always @(posedge clk)
begin
if(rst)
current_state <= IF;
else
current_state <= next_state;
end
这里状态采取本地参量和one-hot编码,这样对应状态只需要取一位便可以完美分别,实用性很强。
/*
* ===========================================================================
* //时序部分:包含下一状态选择;PC选择
* ===========================================================================
*/
wire NOP = !(|IR);//用来确认当前译码是否可读,否则直接PC+4进下一跳。
always @(*)
begin
case(current_state)
IF: begin//无条件进ID
next_state = ID;
end
//译码阶段:若指令有效,则进入执行阶段。
ID: begin
if(NOP) next_state = IF;
else next_state = EX;
end
//执行阶段:进行分流进入三个状态。
EX: begin
if(RI | IB | Jp) next_state = IF;//这里没有考虑RJ指令的问题
else if(R_type | IC | J_wen) next_state = WB;
else next_state = MEM;
end
//内存:从LS中选择
MEM: begin
if(IL) next_state = WB;
else next_state = IF;
end
//写回,无条件进IF
WB: begin
next_state = IF;
end
endcase
end
由于我们实现的是一个十分简单的CPU,所以本来应该放入时序部分的电路部分就暂时归于组合逻辑了。
6.2 PC怎么跳?
CPU一个很重要的地方就是PC的正确,它确定了下一条指令的位置。若是错了,则整个程序很难正确。
首先,需要了解时序逻辑的非阻塞赋值:
- 在进入always语句时计算右侧值,然后在下一次进入时,将右侧值统一赋给左侧。
所以这周期的变化,下周期开头才会变化。
//PC 行为--------------------------------------------IMPORTANT
always@(posedge clk)begin
if(current_state[0]) reg_PC <= PC;//if
else reg_PC <= reg_PC;
end
always@(posedge clk)begin
if(rst) PC <= 32'b0;
else if(current_state[0] & ~rst) PC <= PC + 4;//if
else if(current_state[2] & ~rst) PC <= NEW_PC;//ex
else PC <= PC;
end
在IF阶段,已经读入指令,所以PC直接跳转+4;等到了EX阶段,然后再考虑新PC是怎样的。
reg_PC是用来存储当前指令的PC值,给JALR指令使用。
6.3 储存信息
PC的跳转引来一个问题,也就是IF过后,PC就变化了,而Instruction也会发生变化,这时就需要用一个IR寄存器来存储指令。另外一个需要存储的值就是读进来的内存值。
PC一变化,与之相连的组合逻辑模块便会变化,这就是为什么必须要存储。
always@(posedge clk)begin//IR
if(current_state[0] & ~rst) IR <= Instruction;//IF
else IR <= IR;
end
always@(posedge clk)begin//从内存中读出的数据
if(current_state[3] & ~rst) mem_data <= Read_data;
end
然后保证寄存器和内存写和读的信号只在对应状态才能拉高即可。
7 实验内容
基于之前的设计构建真实内存的访问,以及IO外设访问。
- 硬件:改进基于理想内存的处理器,访问真实内存通路
根据握手机制等待访存延时。
- 软件:基于访存接口,实现IO外设访问,支持字符串打印。
核心就是IO空间映射
8 握手
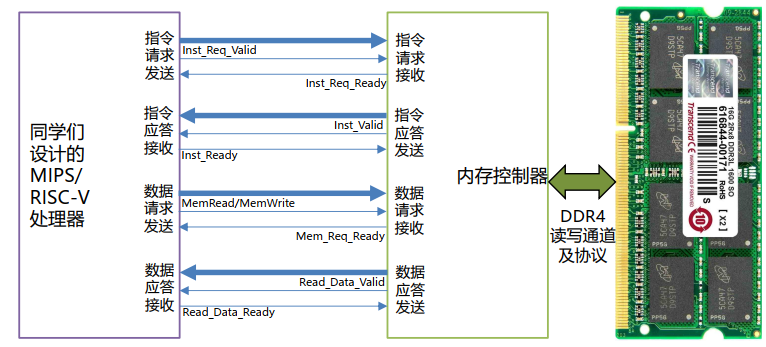
以指令为例。
- 当我需要指令时,把Inst_Req_Valid拉高,传递我需要指令的讯息。表明此时我正处于需要指令的状态。
- 而内存收到Inst_Req_Valid后,知道我们需要指令,于是把Inst_Req_Ready拉高,表示我已受到,开始准备。
- 当我得知内存已经开始准备把内存传给我时,我就把Inst_Ready拉高,表明现在我已经准备好接受正确的指令。
- 当内存把指令准备好,会将Inst_Valid一并拉高,表明我已经传输正确的指令。
以上的这些行为就是下图$IF\to IW\to ID$的行为。
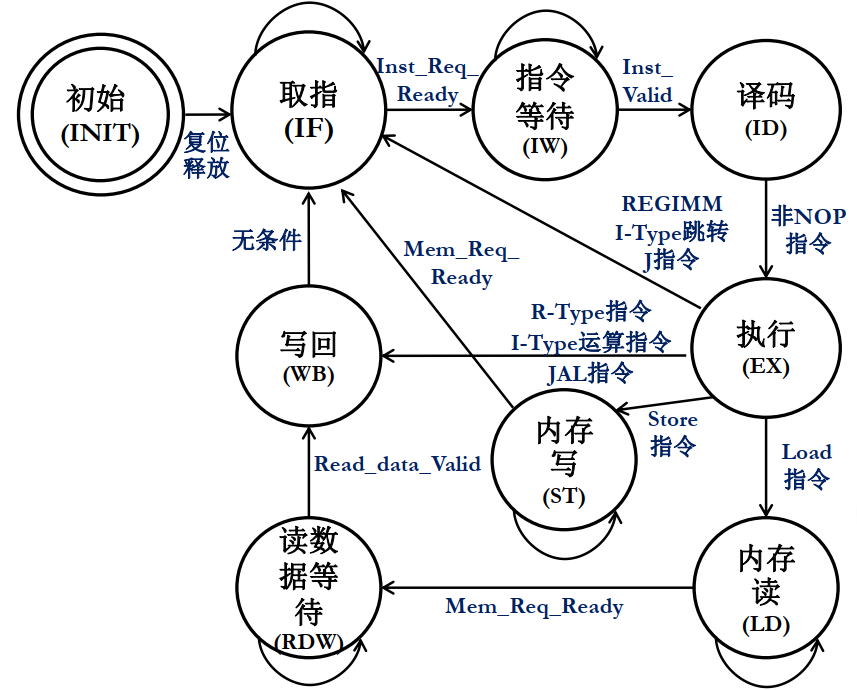
现给出指令部分的操作。
...
INIT:begin
next_state <= IF;
end
//取指:等待Inst_Req_Ready
IF: begin
if(Inst_Req_Ready)
next_state <= IW;
else
next_state <= IF;
end
//等待指令:等待Inst_Valid
IW:begin
if(Inst_Valid)
next_state <= ID;
else
next_state <= IW;
end
...
//IF:
assign Inst_Req_Valid = current_state[1];
//IW:
assign Inst_Ready = (current_state[2] || current_state[0]);
9 通用异步串行收发器 UART
UART,Universal Asynchronous Receiver/Transmitter。
用于计算机与外部设备、计算机与计算机之间进行通信,俗称“串口”。
虽然看起来复杂,但实际上就是访问特定的内存空间,对于C来说要用volatile关键字放置编译器将它优化成寄存器变量。最后导致无法实时改变。
C代码如下:
int puts(const char *s)
{
//TODO: Add your driver code here
int i = 0;
while(s[i] != '\0')//是否结束
{//传输队列是否为满
while((*(uart+REAL_UART_STATUS) & UART_TX_FIFO_FULL));
*(uart+REAL_UART_TX_FIFO) = s[i];
i++;
}
return i;
}
10 需要译码的37条指令
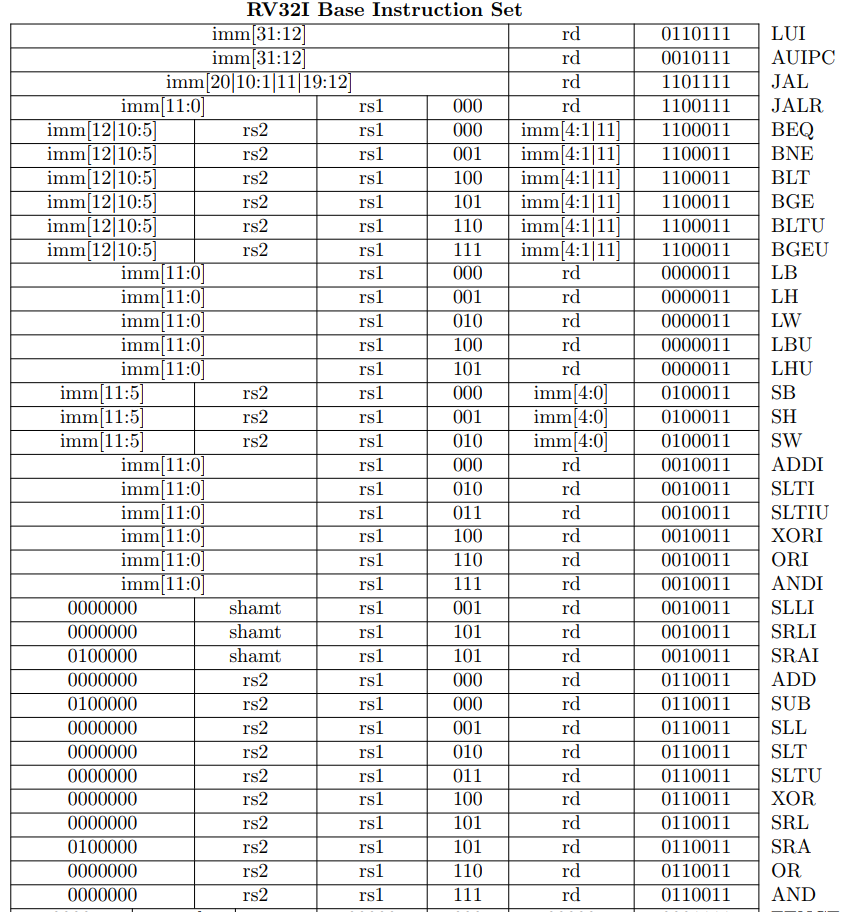
指令译码是一个很重要的地方,而且架构PC和MIPS也有部分区别。
本文参考了两篇文章,一篇为翻译,一篇为讲解。
11 解释
一个需要解释的地方是,MIPS的PC指令多是对PC+4操作;而RISCV是对PC操作。
11.1 LUI与AUIPC
- 将立即数放置到高20位,并且末尾全部补0。这一步也可以用移位器来完成。
- LUI指令就存入rd寄存器;而AUIPC则是将当前指令的PC和第一步的结果相加,写入rd寄存器。
11.2 JAL与JALR
- 两者都将当前PC的下一条指令传给rd。
- 而对PC的操作则不尽相同:
- JAL将当前PC和调整后的立即数相加。
- JALR将寄存器里的数和符号扩展后立即数相加,末尾置0.
JAL的末尾0由PC和左移保证;而JALR强制置0。</br> 立即数调整,只需要看[]中对应的位即可。
11.3 分支指令
rs1和rs2寄存器内值比较,末尾0由移位保证。
若达成条件则和调整后的Imm相加。
11.4 Load指令
imm符号位扩展和rs1中数相加后得到地址,随后和MIPS一样的操作。
11.5 Store指令
rs1寄存器取数,载入M[R[rs2]+sign_ex(imm)]
11.6 IC指令
就那样吧,后面都差不多。
12 译码
总的来说,RISCV比MIPS要轻松一点。
因为RISCV的opcode不仅和操作有关,还和操作对象有关。比如双寄存器和单寄存器十分都是有一位为1.
13 性能对比分析
通过性能计数器显示,有部分程序的指令数减少十分显著。
- 取指
取指阶段,RISCV无延迟槽。由于没有加入流水线,那么也不太能分析出有什么具体变化。
- 译码
- 所有高位扩展的最高位都是指令的最高位。
- opcode十分整齐,细分指令功能用一个三位的func做了。这一点比MIPS要优秀。
- 指令行为上看,RISCV的指令行为也比较统一,读写寄存器的地址和位置都比较固定。
- 执行
考虑微指令架构的话,更方便的译码应该能带来更简易的、更迅速的执行。
影响ISA性能的因素还有很多,比如对应处理器架构的优化、编译器的优化、微指令操作码的优化。不同的ISA也可能有不同的强项,由于我们只用了最粗浅的Verilog进行顶层设计实现,所以对其的讨论仅仅停留在纸上。也仅仅只能停留在纸上了。
14 DNN
DNN,也就是深度学习网络模型。
本次实验的目的是在CPU上支持乘法指令,并且用c代码完成最基本的卷积运算和池化运算。